

![]()
Kullandığınız veritabanı tablolarında özellikle Db tarafında verilere hızlı ulaşma veya performans artışı sağlamak için Index yapısı kullanılabilir. Fakat bunun da kendine göre şartları ve durumları bulunmaktadır. Biz Microsoft SQL Server da nasıl kullanıldığına bakacağız ama diğer Db lerde de mantık aynı olacaktır. Index yapısı veritabanımızdaki tablolara hızlı bir şekilde ulaşmamızı ve sorguların daha hızlı çalışmasını sağlar. Yabi bizi nokta atışı sonuçlara götürebiliri. index özel bir sıralama oluşturur. MS-SQL de tablo oluşturuken yaptığımız Unique Key ve Primary key de bir indextir.
Index verileri sıralayıp düzenlediği için data çekerken (select) sorguları hızlandırı fakat insert , update , delete gibi işlemlerde (bu işlemlerden sonra tekrar index te yazma ve düzenleme yapıldığı için) ek işlem çıkardığı için yavaşlatmaktadır.
Index tablo oluşturuken eklenebileceği gibi sonradan da eklenebilir.
Index Türleri
1-Clustered Index: Her tabloda yalnızca bir tane olabilir. Tabloyu fiziksel olarak düzenler ve sıralar. Normal tablo tanımlarken oluşturduğumuz primarykey de bir clustered index’tir.
2-Non-Clustered Index: Bir tabloya birden fazla non-clustered index eklenebilir.. Bu index ler, tablonun fiziksel düzenini değiştirmezler (arka tarafta yeni bir tablo oluşur ve bu tablo indexlenen kolona karşılık gelen alanı tutar) , ancak index sütunlarını sıralarlar. Çalışma mantığı Kitapların giriş sayfasındaki index(içindekiler) mantığı gibidir. İçindekilerde ki aradığınız konuya bakıp direkt o sayfaya gitmek gibi.
3-Unique Index: Bu indexler, sütunlardaki değerlerin benzersiz olduğunu belirtir
Index oluşturma şablon sorgusu;
|
1 2 3 4 |
CREATE INDEX index_adi ON tablo_adi (sutun1, sutun2, ...); |
Şimdi Personel adındaki 160.000 kayıtlık tablodan bir tane kayıt çekeceğiz sonrada index oluşturarak aynı kaydı çekip performans sonuçlarına bakacağız.
1-önce statistics açtım ve Estimated ile datanın Table Scan ile kaç sayfaya bakarak nekadar sürede getirdiğine baktım.
|
1 2 3 4 5 6 7 8 9 |
set statistics IO ON set statistics TIME ON //kapama set statistics IO OFF set statistics TIME OFF |
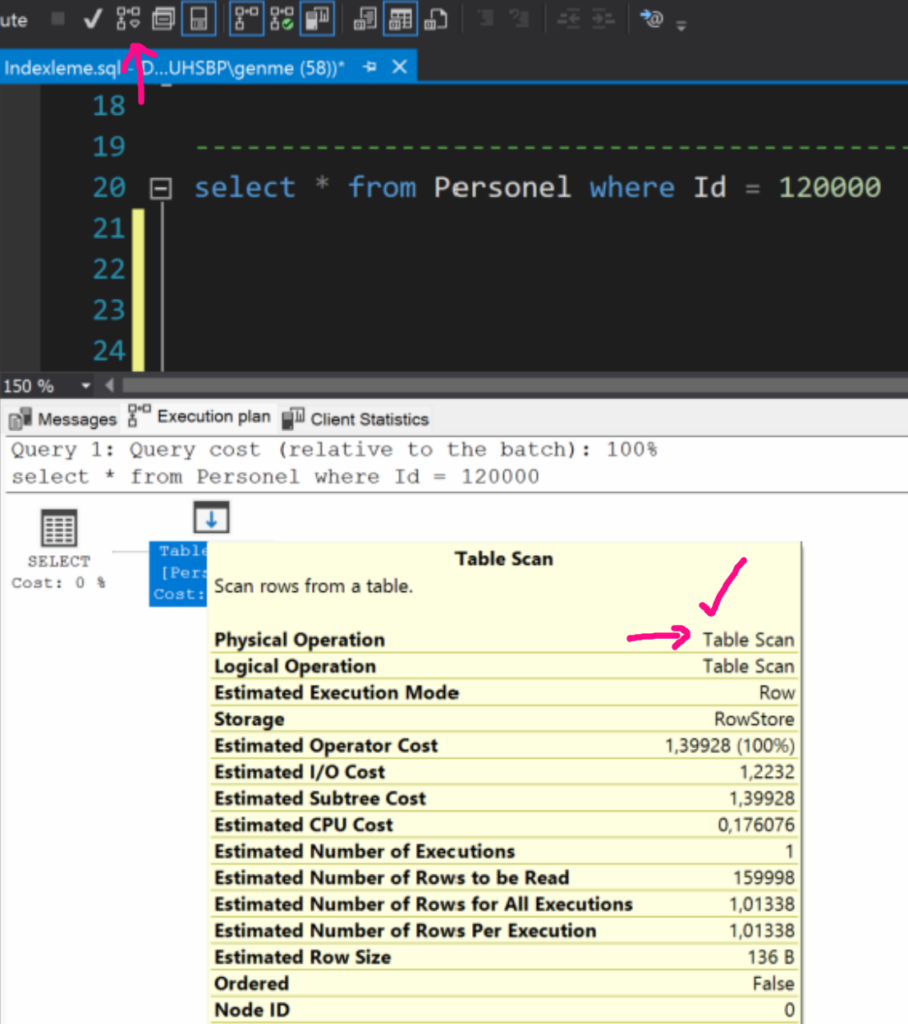
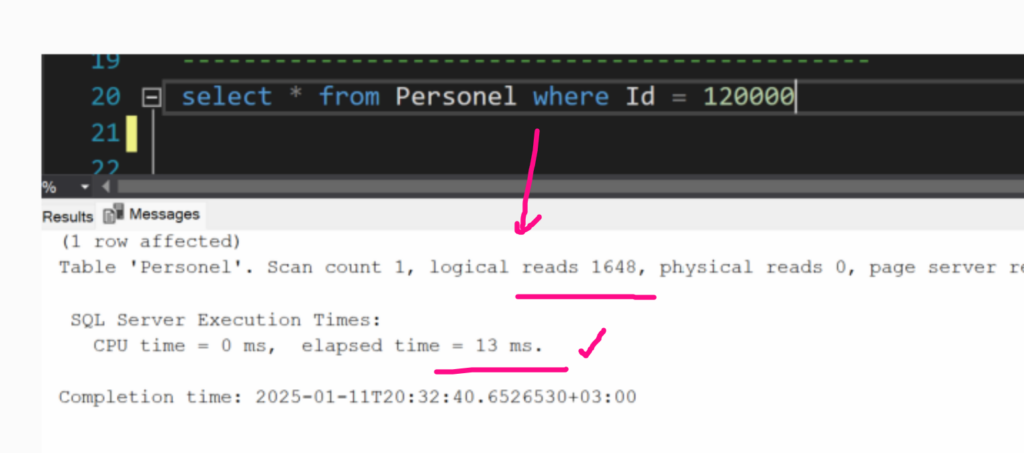
görüldüğü gibi Table scan ile 1648 sayfaya bakarak 13 ms de okuğu görünüyor.
2-Şimdide Personel Id üzenden clustered Index oluşturup aynı şeyi deneyelim.
|
1 2 3 |
create clustered Index Pers_1 on Personel(Id) |
statistics kapadım ve Estimated ile datanın clustered Table ile kaç sayfaya bakarak nekadar sürede getirdiğine baktım.
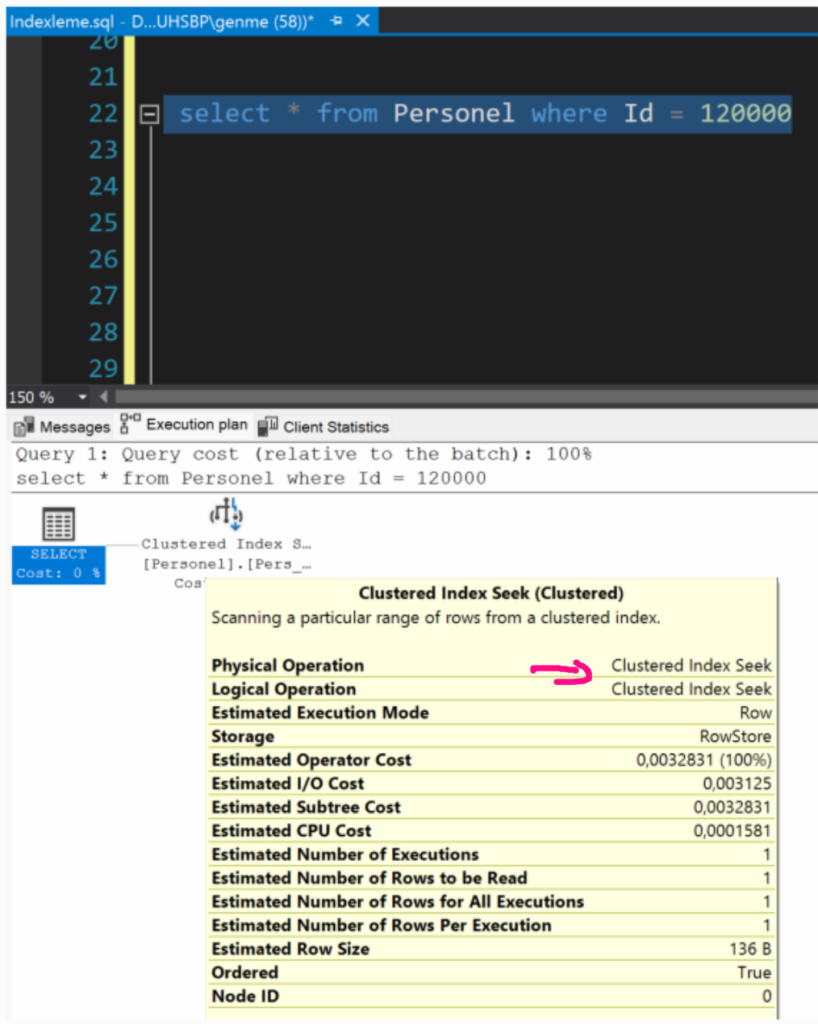
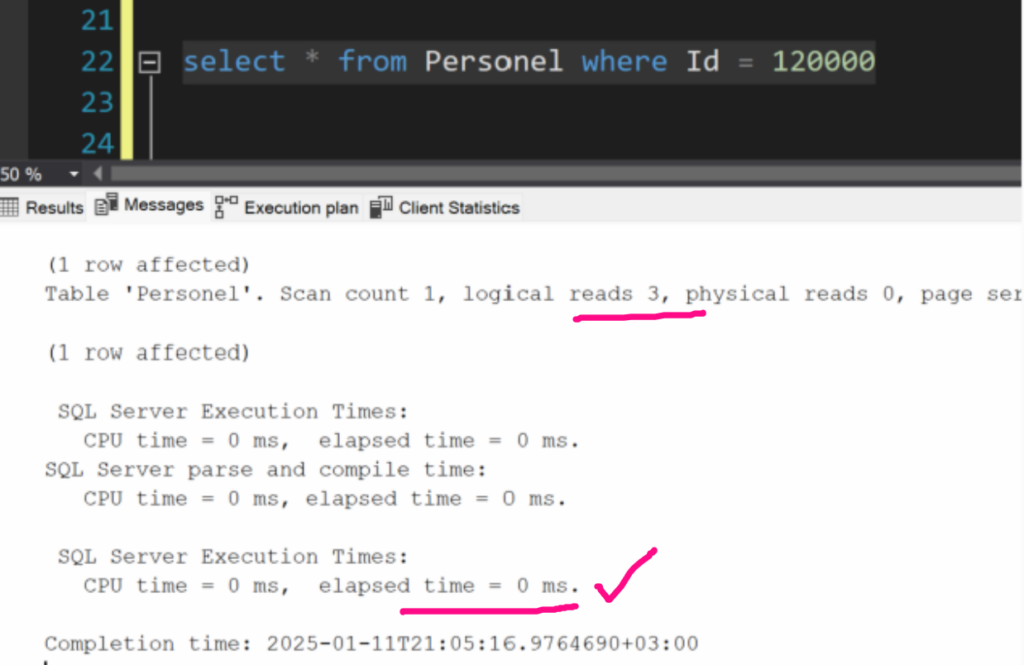
görüldüğü gibi 1648 sayfa yerine 3 sayfaya bakmış ve süre 0 ms
Oluşturduğumuz ındex in adını ve tipini görmek için de aşağıdaki sorguyu çalışturarak bakabiliriz
|
1 2 3 |
select * from sys.indexes where OBJECT_NAME(object_id) = ‘Personel’ |
Index i silmek için de aşağıdaki sorgu kullanılabilir
|
1 2 3 |
DROP INDEX Pers_1 ON Personel |
Son olarak ;
Büyük tablolarımız ve çok fazla datalaeımız varsa, sorgu sonuçlarımız çok uzun sürede geliyorsa , datalarda fazla NULL alan yoksa , sürekli kullanılan sütün var ise indexleme kullanımı doğru bir yöntem olacaktır ve işimizi çok kolaylaştıracaktır. Yanlış kullanılan indexleme ise aksi sonuçlar doğurabilir.
sağlıcakla kalın….






Bir yanıt yazın